Accuracy / Repeatability Improvements
So far I have been sticking fairly close to Prusa’s implementation for the tap decomposition. But in October I started messing with various ideas to improve things. I kept seeing seemingly random tap decomposition errors/failures that manifested in a few ways:
- Crazy plots in the debug tool for data that looked reasonable. This caused the tap to fail.
- Random probes where the elbow just looked clearly wrong. This would ruin the range of otherwise good set of probes.
Now others are starting to use the test branch and I’m getting access to their probe data. We can see similar effects in their data. I’ve tracked this down to 3 root causes:
Pullback Move Acceleration Data is Unreliable
The samples between when the pullback move starts and when the z axis reaches cruising speed can be chaotic. Sometimes its a flat line, sometimes its a curve, sometimes it looks like movement starts instantly. Making these samples part of the dataset caused the elbow finder to have to solve some kind of Z shaped plot, some of the time.
This had a “tail wagging the dog” effect where the other end of the line would be shifted. The solution here is pretty simple, just completely ignore these samples. I get the timing for the moves from the trapq so I can just drop those samples from the analysis.
This helped but there were still some cases this didn’t fix.
Curves in the Decompression Line
This was way more subtle. The vertical pullback move can sometimes be curved! This is not the underlying assumption of linear regression in this context. Curves really mess with the two_lines_best_fit elbow finder as it tries to optimize a line to pass through that curve. That optimal line is a chord that is tangent and bisects the curve. This is exaggerated but it looks like this:
This puts the ends of the line pretty far away from the actual elbow point causing a large z error (errors in x are error in time which is error in z). The solution I’ve come up with is to break these curves into 2 lines and treat them as two separate line segments. This lends higher importance to points near the elbow causing its position to shift much closer to the real elbow.
The decompression line can be convex, concave or straight. So the solution needs to work equally well for all of those cases. Splitting by time doesn’t work because it unfairly puts puts more information about the curve in one half or the other. I also tried using the elbow finder but this performed poorly. What tested the best is splitting the line vertically on the force axis. This yields 2 line segments that are much closer to reality:
If the line is straight the solution wont change but in curved conditions it improves. I built a notebook to test this on some “difficult” probe data, comparing the old a new approach. Here is a really clear example:
This plot shows the original algorithm in red and the new version in green. The thing to notice there is that the green dot at the last elbow has shifted significantly to the right (every sample here ~= 1 micron in z). There is also a new green dot half way up the pullback line that is the intersection of the two new line segments. And you can see that red line forming the chord through the curve that I sketched earlier.
Here is an example where the line is slightly convex. It still results in a lot or error in the red line:
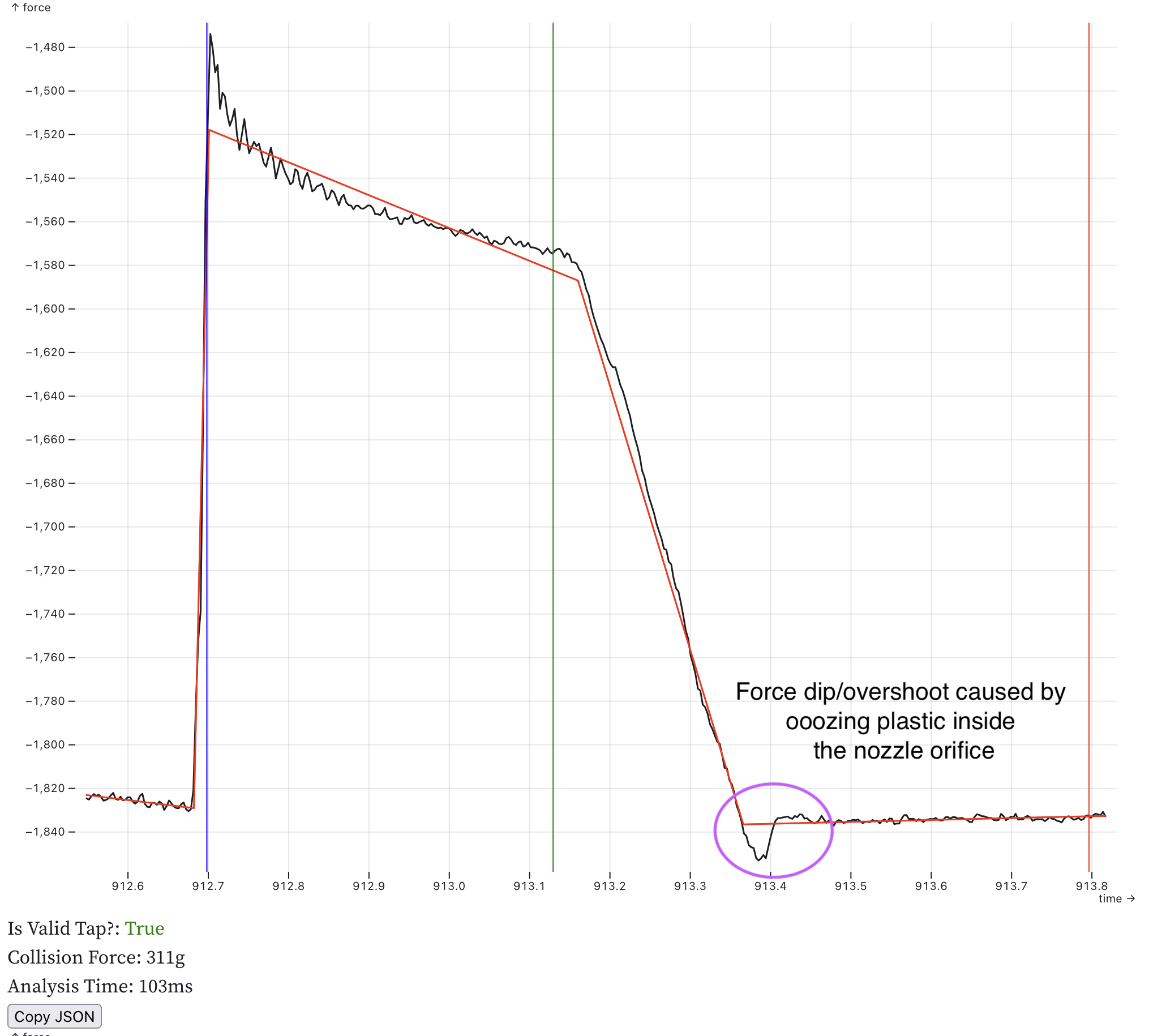
There are new safety checks with this change. If the tap data is noisy and the tap compression force is small its possible for the split lines to look like noise. So there is a new check for the noise and the curve splitting optimization is disabled if it fails. the split lines need to have points that are more than 2x the noise in amplitude away from the mean. This is an example plot where the safety kicks in and refuses to split the decompression line:
I’m not sure yet how I want to surface this. Its not a failure, but it may mean your setup isn’t optimal. A lower noise sensor, a more sensitive load cell, or just probing faster or with a higher trigger threshold could help.
Kneedle Doesn’t Like Noise
The last batch of issues happened when the Kneedle elbow finder was used to pick an elbow on noisy data. Usually this was the initial collision elbow. That data is noisy because the printer is moving faster when probing downwards. If the noise caused the Kneedle algorithm to pick a bad elbow it could wreck the plot and fail the internal sanity checks.
So I’ve dropped the kneedle algorithm entirely and put some work into optimizing the numpy.linalg.lstsq usage:
- The nd arrays and transpose matrix get allocated once. Everything is now views, saving a bunch of wasteful memory allocations.
- I set the data type of the nd array to
float32. This aligns much better with the capabilities of the FPU on the Pi for a nice speedup (examples from others).
- Limit the number of points processed. The code now clips the dataset at 2x the width of the pullback move for any elbow calculation.
Printing with this feels like magic. It just works. I did 3 back-to-back bed sized first layers and they were all defect free. No high spots and no low spots. Just fully fused sheets of plastic.
I still need to do some more work to get these changes pushed out to the testers, but they are coming soon.